こんばんは。ヤマモトです。
コーヒーが美味い。なかなかの美味ですわ。
ヤマモトは近所のお店で豆を選んで焙煎してもらって家で挽いて飲む派です。(長い)
カフェインは眠気覚ましにも良いですが、脂肪燃焼効果も高まるのでよく飲む。
・・・が、こんな時間に飲むから眠れなくなることも多々ある。。。みなさんはマネしないでね。
さてさて。python webスクレイピング企画を進めているわけだが、
前回は連載一覧を無事取得するところまでできた。

今回はそこから少しplus ultraで、画像取得までやったのと、
前回作成のスクリプトから微修正したので、そちらをご紹介。
webスクレイピングとしては完結編。(のはず)
前回書いたコードのおさらい
前回までに以下のコードを書いた。
import requests
from bs4 import BeautifulSoup
# ジャンプのサイトからHTMLを取ってくる。
url = 'https://www.shonenjump.com/j/rensai/'
res = requests.get(url,timeout=3)
# 文字コードを推定して適宜変換する関数を使用。
res.encoding = res.apparent_encoding
# html.parserに渡してHTMLの解析を行う。
soup = BeautifulSoup(res.text, "html.parser")
# 連載一覧の部分だけを抽出
elems = soup.find_all(class_="sakkaName")これで変数elemsに連載作品名がlist形式で格納されている状態。
前回からの微修正
「連載一覧」表示の課題
前回書いたコードだと、ジャンプの連載一覧(https://www.shonenjump.com/j/rensai/)から作品名を取得する仕様だったが、例えば今週時点で取得するとこんな感じ。
elems
[<div class="sakkaName">『ONE PIECE』尾田栄一郎</div>,
<div class="sakkaName">『HUNTER×HUNTER』冨樫義博</div>,
<div class="sakkaName">『僕のヒーローアカデミア』堀越耕平</div>,
<div class="sakkaName">『ブラッククローバー』田畠裕基</div>,
<div class="sakkaName">『呪術廻戦』芥見下々</div>,
<div class="sakkaName">『夜桜さんちの大作戦』権平ひつじ</div>,
<div class="sakkaName">『アンデッドアンラック』戸塚慶文</div>,
<div class="sakkaName">『マッシュル-MASHLE-』甲本一</div>,
<div class="sakkaName">『僕とロボコ』宮崎周平</div>,
<div class="sakkaName">『高校生家族』仲間りょう</div>,
<div class="sakkaName">『SAKAMOTO DAYS』鈴木祐斗</div>,
<div class="sakkaName">『逃げ上手の若君』松井優征</div>,
<div class="sakkaName">『ウィッチウォッチ』篠原健太</div>,
<div class="sakkaName">『アオのハコ』三浦糀</div>,
<div class="sakkaName">『PPPPPP』マポロ3号</div>,
<div class="sakkaName">『あかね噺』原作:末永裕樹 作画:馬上鷹将</div>,
<div class="sakkaName">『地球の子』神海英雄</div>,
<div class="sakkaName">『すごいスマホ』冨澤浩気・肥田野健太郎</div>,
<div class="sakkaName">『ALIENS AREA』那波歩才</div>,
<div class="sakkaName">『ルリドラゴン』眞藤雅興</div>,
<div class="sakkaName">『大東京鬼嫁伝』仲間只一</div>]作品が連載開始した順に並ぶため、例えば今週巻頭で新連載の「大東京鬼嫁伝」は末尾に、休載中の「HUNTER×HUNTER」は二番目に来ている。
ヤマモトは基本は前からジャンプを読んでいるので、正直この並びは記事を書くときちょっと面倒。。。
「掲載順」を取得したい
できれば掲載順で欲しいな~~
ということで、ジャンプ公式サイトを探していると、、、あるではないですか。
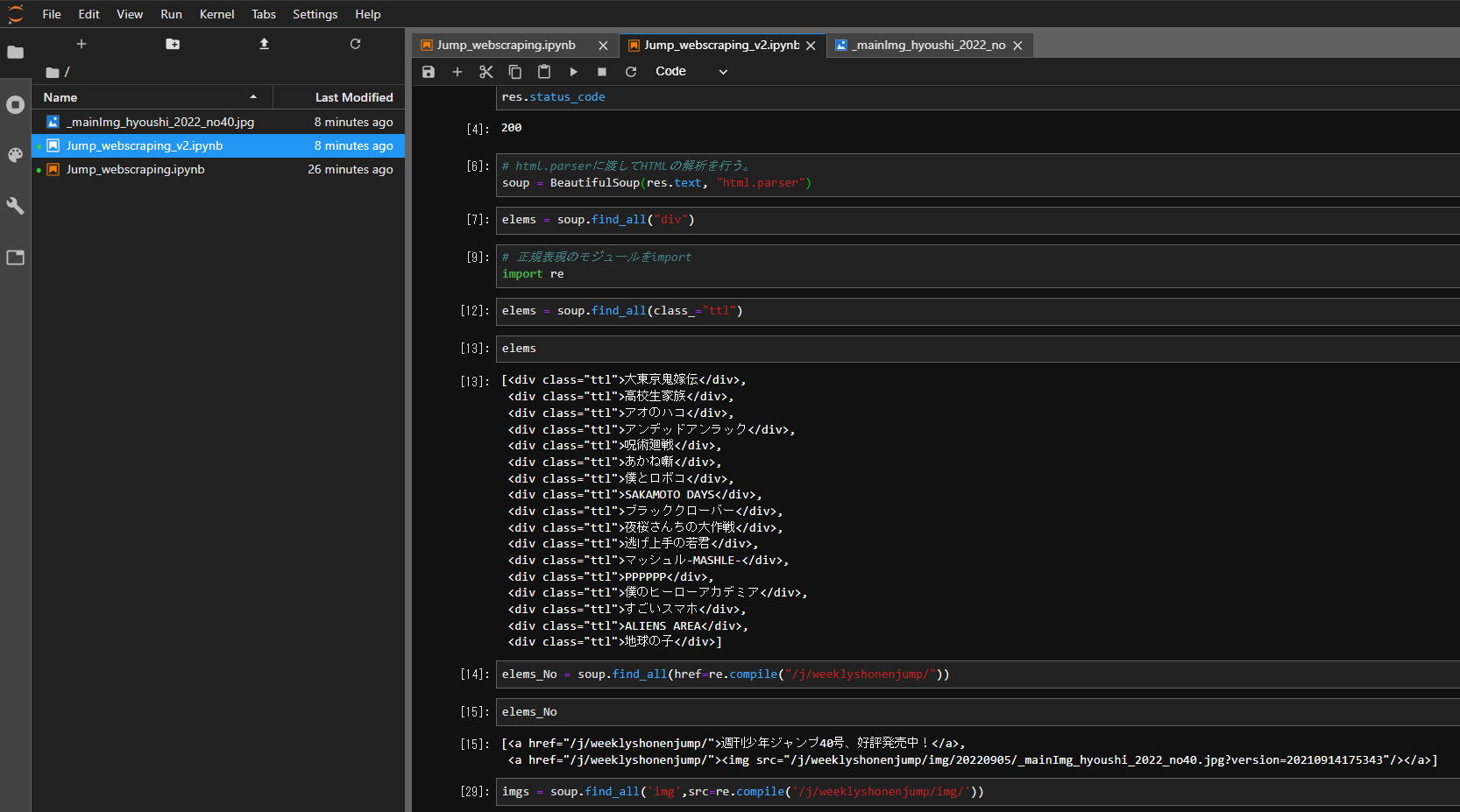
「今号のジャンプ情報」(https://www.shonenjump.com/j/weeklyshonenjump/)というページがまさに求める答え。URLも毎週固定のようなので、こっちから情報を引っ張ってきた方が良い。
ということで、コードを少し修正。
## 途中省略 ##
# ジャンプのサイトからHTMLを取ってくる。
- url = 'https://www.shonenjump.com/j/rensai/'
+ url = 'https://www.shonenjump.com/j/weeklyshonenjump/'
# 連載一覧の部分だけを抽出
- elems = soup.find_all(class_="sakkaName")
+ elems = soup.find_all(class_="ttl")出力結果はこんな感じ。
elems
[<div class="ttl">大東京鬼嫁伝</div>,
<div class="ttl">高校生家族</div>,
<div class="ttl">アオのハコ</div>,
<div class="ttl">アンデッドアンラック</div>,
<div class="ttl">呪術廻戦</div>,
<div class="ttl">あかね噺</div>,
<div class="ttl">僕とロボコ</div>,
<div class="ttl">SAKAMOTO DAYS</div>,
<div class="ttl">ブラッククローバー</div>,
<div class="ttl">夜桜さんちの大作戦</div>,
<div class="ttl">逃げ上手の若君</div>,
<div class="ttl">マッシュル-MASHLE-</div>,
<div class="ttl">PPPPPP</div>,
<div class="ttl">僕のヒーローアカデミア</div>,
<div class="ttl">すごいスマホ</div>,
<div class="ttl">ALIENS AREA</div>,
<div class="ttl">地球の子</div>]おおおおお。ばっちぐー
本題: 画像取得をやってみる。
コード自体は実は数行で終わるのだが、ちょっと躓いたので備忘録的にまとめておく。
画像URLの取得
まずはダウンロードしたい画像のURLを取得する。
これは上記のwebスクレイピングで取得したHTMLに画像のURLも記載されているので、BeautifulSoupで取得した解析結果からURLを持ってくる。
HTMLを見てみると、ジャンプの表紙画像は以下のURLのようだ。
- https://www.shonenjump.com/j/weeklyshonenjump/img/20220905/_mainImg_hyoushi_2022_no40.jpg?version=20220902145720
タグはimgだが、imgを指定すると他の画像との区別ができない。
そこで、「j/weeklyshonenjump/img」の部分を検索対象とすることで、表紙の画像だけを選別する。
検索は正規表現で行う。
コードで書くとこんな感じ。
# 正規表現のモジュールをimport
import re
# 表紙画像の取得。srcの指定に正規表現を用いている。
imgs = soup.find_all('img',src=re.compile('/j/weeklyshonenjump/img/'))ちなみに、今回は表紙を指定しているので返り値は一つの画像URLだが、find_allの返り値はリスト型なので、要素を取得する際は注意。
# 取得したURLを表示
imgs[0].get('src')
'/j/weeklyshonenjump/img/20220905/_mainImg_hyoushi_2022_no40.jpg?version=20210914175343'ここでヤマモトは躓いてしまったのだが、↑のURLは冒頭のサーバ名「https://www.shonenjump.com」がカットされているため、後述の画像保存の際は正式なURLパスを渡してあげる必要がある。
# 正式なURLパスを作成
img_link = "https://www.shonenjump.com" + imgs[0].get('src')画像の保存
保存するときのファイル名はなるべく取得したときのままでいきたいので、一工夫加える。
具体的には、ファイル名を画像URL内から部分取得する。その際、毎週ファイル名が変わるため正規表現で取得する。
## 正規表現で画像URLからファイル名の箇所だけ抽出。
re.search(r'_mainImg_hyoushi_.*_.*.jpg', str(imgs[0])).group()
'_mainImg_hyoushi_2022_no40.jpg'それでは実際に保存してみる。
# 保存する際のパス、ファイルネームを定義。
filename = "./%s" % re.search(r'_mainImg_hyoushi_.*_.*.jpg', str(imgs[0])).group()
r = requests.get(img_link)
with open(filename,'wb') as file:
file.write(r.content)今回はとりあえずカレントディレクトリを指定したので、ipynbと同じフォルダに「_mainImg_hyoushi_2022_no40.jpg」のファイル名でちゃんと保存されている。
参考にした記事
はい、ということでお疲れさまでした。
これで必要な情報はいつでも取得できるようになったかな。
あとはこの情報を元に記事のテンプレート作成までできたら、、、完璧や。
次回は「pythonでwordpressを投稿してみた」かな。


コメント