こんばんは。もしくはかなりおはようございます。ヤマモトです。
なんでこんな夜更けに起きているかというと、そう。掲題の件ですよ。
ついに完成したんすよ、力作が!!!
あ~~ 長かった~
めっちゃ調べまくった。めっちゃトライ & エラーだった。
もう眠すぎて力つきそうだから、早く本題入ろう。
完成したコード
整理できそうなところはまだありそうだけど、とりあえず現時点でのやつ。
import os
import json
import re
# webスクレイピング用のモジュール
import requests
from bs4 import BeautifulSoup
#####################################
### ジャンプからデータ取得をする部分 ###
#####################################
# ジャンプのサイトからHTMLを取ってくる。
# URLは今週号のページ
url = 'https://www.shonenjump.com/j/weeklyshonenjump/'
res = requests.get(url,timeout=3)
# 文字コードを推定して適宜変換する関数を使用。
res.encoding = res.apparent_encoding
# html.parserに渡してHTMLの解析を行う。
soup = BeautifulSoup(res.text, "html.parser")
# 連載一覧の出力
jump_list = soup.find_all(class_="ttl")
# 余計なタグを削除
jump_list = list(map(lambda x: re.sub('<div class="ttl">(.+)</div>','\\1',str(x)),jump_list))
# 号数の出力
jump_No = soup.find_all(name="p",text=re.compile(".*表紙"))[0]
# 余計なタグを削除
jump_No = re.sub('<p>(.+) 表紙</p>','\\1',str(jump_No))
# 表紙画像の取得
imgs = soup.find_all('img',src=re.compile('/j/weeklyshonenjump/img/'))
img_link = "https://www.shonenjump.com" + imgs[0].get('src')
# 保存する際のパス、ファイルネームを定義。
file_path = ".\\Pictures\\ブログ用\\ジャンプ表紙\\%s" % re.search(r'_mainImg_hyoushi_.*_.*.jpg', str(imgs[0])).group()
# 画像の保存
r = requests.get(img_link)
with open(file_path,'wb') as file:
file.write(r.content)
######################
### WordPressに投稿 ###
######################
# ブログのURL
blog_url = 'https://arefukeblog.com/'
# WordPressのユーザー名
api_user = 'hogehoge'
# アプリケーションパスワード
api_password = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
### 表紙画像のアップロード ###
file_name = os.path.basename(file_path)
# Media APIのURL
post_api_url = f'{blog_url}/wp-json/wp/v2/media/'
post_header = {
'Content-Disposition': f'attachment; filename="{file_name}"',
}
media = {'file': open(file_path,'rb')}
# 画像のアップロード
media_response = requests.post(post_api_url, headers=post_header, files=media, auth=(api_user, api_password))
# 画像のIDを取得
media_id = json.loads(media_response.content.decode('utf-8'))['id']
# キャプションの生成
caption = '出典:<a href="https://www.shonenjump.com/" target="_blank" rel="noopener">集英社『週刊少年ジャンプ』公式サイト</a>'
# 画像にキャプションを追加
post = {'caption': caption
}
# 画像修正のリクエスト
media_response_2 = requests.post(f'{blog_url}/wp-json/wp/v2/media/{str(media_id)}', headers=post_header, json=post, auth=(api_user, api_password))
### 記事の作成 & 投稿 ###
# title
title = f'※テスト※【週刊少年ジャンプ】{jump_No} 感想 テスト'
# 記事の定型文
sub1 = '<h2>今週号の各作品の一言感想</h2>'
subsub = "".join(list(map(lambda x: re.sub('(.+)','<h5> \\1</h5>',str(x)),jump_list)))
body = "<hr>その他の作品はまだ読めていないので悪しからず。"
sub2 = '<h2>次号への抱負</h2>'
contents = sub1 + subsub + body + sub2
# スラッグ
URL_slug = re.sub('([0-9]{4})年([0-9]{2})号','jump-review-\\1-\\2',jump_No)
# 送信する記事データ
post_data = {
'title': title,
'content': contents,
'slug': URL_slug,
'categories': [7,11],
'status': 'draft', # draft=下書き、publish=公開 省略時はdraftになる
'featured_media': media_id
}
# Post APIのURL
post_api_url = f'{blog_url}/wp-json/wp/v2/posts/'
# 記事投稿リクエスト
response = requests.post(post_api_url, json=post_data, auth=(api_user, api_password))解説
XML-RPC →REST API へ変更
お気づきの方もいらっしゃるかと思うが、そう。記事投稿のプロセスを変更した。
先日の記事では XML-RPC で奮闘するヤマモトがいたが、今は昔。。。

元々、XML-RPC に思い入れがあったかと言われるとそうでもなく、なんとなくそっちを使っていた。しかし、コードを書き進めるうちに色々と問題が出てきたため変更した。
大まかな変更理由を述べると以下の通り。
XML-RPCだと、画像をキャプション付きでアップロードできなかった。
一番大きな理由はこれ。
XML-RPC は以下のコードで画像を簡単にアップロードできるのだが、逆に言うとそれ以上ができない。
imgPath = filename
with open(filename, 'rb') as f:
binary = f.read()
data = {
"name": filename,
"type": 'image/jpg',
"overwrite": True,
"bits": binary,
}
media_id = wp.call(media.UploadFile(data))['id']調べてみると、アップロード済みの画像であればキャプション情報などの取得はできるらしい。が、どんなに調べてもキャプション追加の項目は見つからず。。。
で、そんな折に代わりに見つかったのが以下のやりとり。
headers = {'Authorization': 'Basic ' + token.decode('utf-8')}
media = {'file': open('img.jpg','rb')}
# first request uploading the image
image = requests.post(url + '/media', headers=headers, files=media)
# get post-id out of the response to the first request
postid =json.loads(image.content.decode('utf-8'))['id']
# set the meta data
post = {'title': 'title',
'caption': 'caption',
'description': 'description',
'alt_text': 'alt_text'
}
# second request to send the meta data
req = requests.post(url + '/media/'+str(postid), headers=headers, json=post) なるほど。REST API だとできるのか。
APIの方が安全そう。
とってつけたような理由w
事実、これについては後から気づいたことだった。
というのも、XML-RPC は記事投稿時の認証に WordPress のアカウント情報を利用する。つまり、WordPressのパスワードを何かしらの方法でpythonのスクリプト内に渡さないといけない。
最初はハードコーディングでパスワードをスクリプト内に記載していたが、「なんか怖くね??」という危機感が徐々に芽生えてきた。
もちろん、暗号化して渡すとか、都度打ち込むとか色々対策はあるのだが、そもそもそんな危ない橋は渡らないというのがセキュリティの鉄則だったりもする。
対して、REST API だとAPI用のパスワードを発行して使うため、なんかあったら再発行したりもできるので、使い勝手が良い。
ということで、後付け的な理由ではあるが、REST API の方を使おうと思ったわけである。
正規表現の大活躍
ヤマモトはあまり正規表現を使ったことが無かったので、今回は試行錯誤で書き進めたわけだが、、、
正規表現、めっちゃ便利やん。
例えば今回だと、HTMLから情報を取ってきているので、余計なタグがついてたり。逆に記事投稿するときはタグを付与しないといけなかったり。
などなど、実は今回作成したコードは文字列処理のオンパレードだったりする。
全部を開設すると長くなるので割愛するが、検索と置換は使えるようになった気がする。
正規表現って、ルールが膨大過ぎて覚えられないから敬遠してたけど、無限の可能性を秘めているんだな、、、としみじみ思った。
今度からはめんどくさい文字列処理が出てきたら、「○○ 正規表現」みたいにググることが増えそう 笑
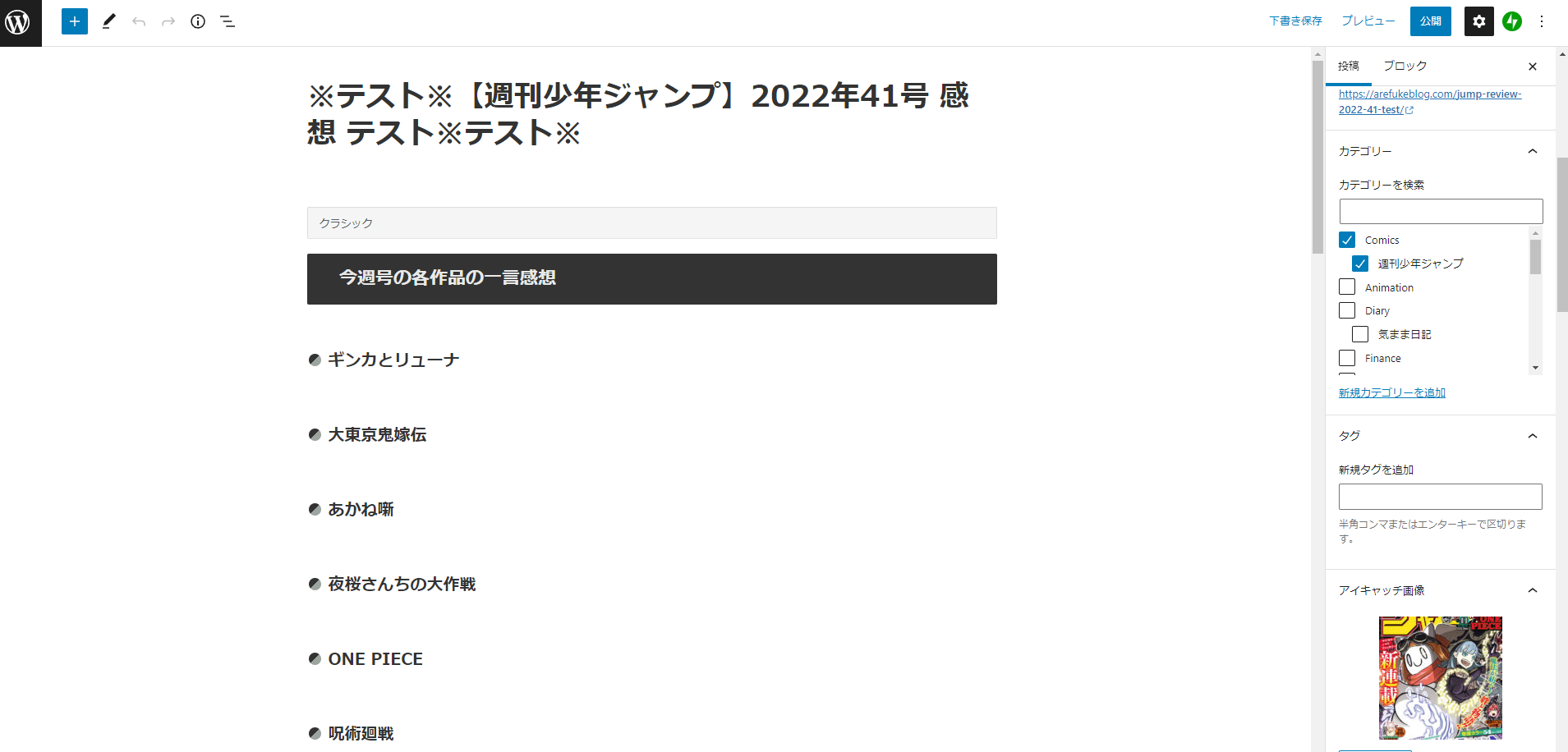
コードを実行した結果
実際に走らせた結果がこちら。
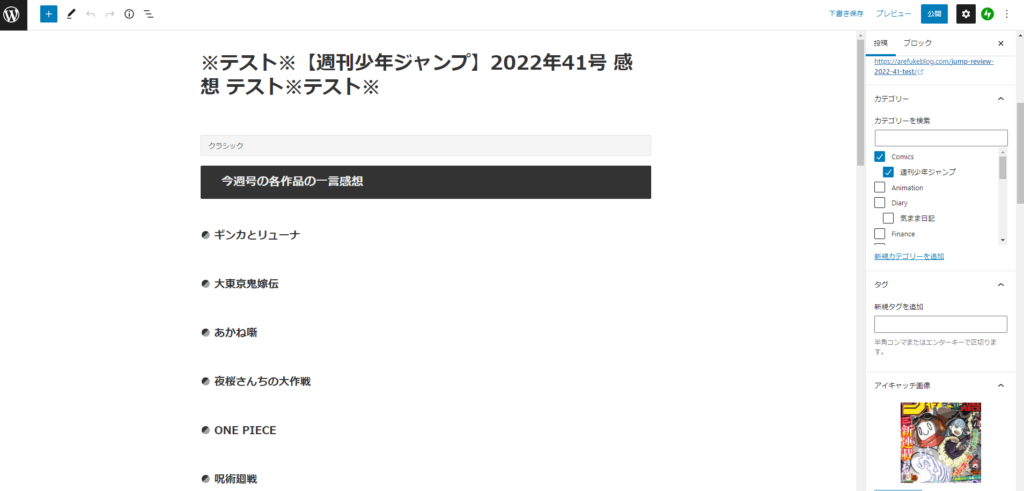
ちゃんと段落も認識してくれているし、パーマリンク、カテゴリ、アイキャッチ画像もばっちり。
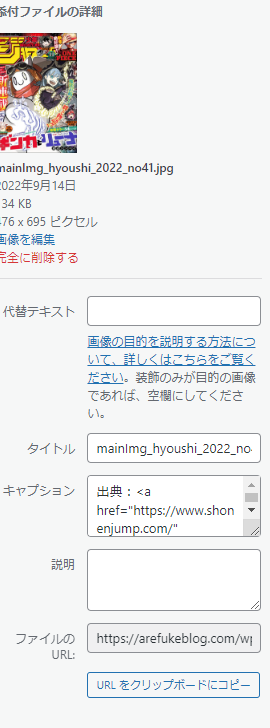
画像についてもキャプション付きでアップロードされている!!!
ということでお疲れさまでした。
朝だよ。完全に。
冷静になってみたが、徹夜してやる作業じゃねえよな 笑
ままま。とりあえず、記事投稿が楽になったよ~ということで、今後はどんどん記事をバッチ化していこうと思う。
・・・明日、ていうか今日、仕事なんだよな。。。

コメント